Computer scientists to unveil ‘sense check’ for AI robots at prestigious conference

University of Leicester computer scientists have developed a ‘sense check’ to reveal whether an AI robot is acting on the right information.
It will allow scientists to determine whether a robot’s actions are being influenced by irrelevant ‘distractions’ in the environment – whether it followed an instruction successfully or not.
Their latest research paper has been accepted to the International Conference on Machine Learning (ICML) 2026 in Seoul, South Korea, one of the world’s leading conferences in artificial intelligence and machine learning, taking place from 6-11 July.
The paper focuses on a central question in modern robotics: how can researchers understand why an AI-enabled robot chooses a particular action?
Vision-Language-Action models are an emerging type of AI system that allow robots to connect what they see, what they are asked to do, and how they physically act. They are a step towards more flexible and general-purpose robots, but their decisions can still be difficult to understand.
A robot may complete a task successfully in one setting but fail when the environment changes. This can happen when the model relies on unintended visual cues, such as shadows, background details, lighting conditions or textures, rather than information that is genuinely relevant to the task.
This new research, led by the Dynamics, Astronautics and Neural Intelligence Lab (DANi Lab) at the University of Leicester’s School of Computing and Mathematical Sciences, takes a step towards better understanding this problem by introducing a way to analyse which parts of an image influence a robot’s actions. The work helps researchers examine whether a model is responding to meaningful task-related information, or whether it may be relying on unreliable cues.
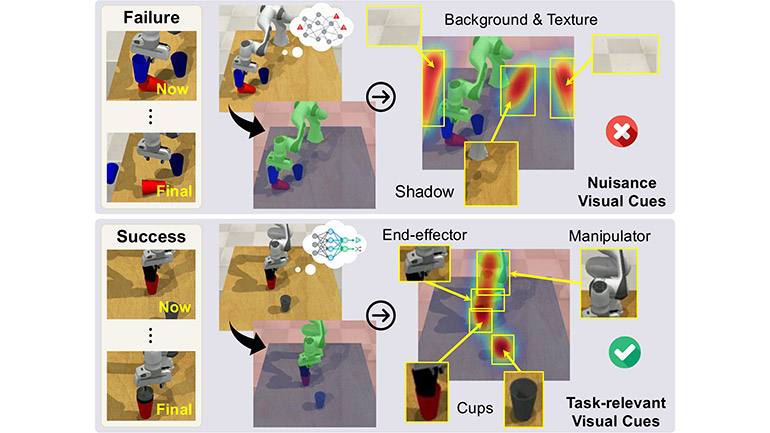
The heatmaps show which parts of an image are influencing the robot’s decision. By hiding different areas of the picture and seeing whether the robot changes its action, we can check whether it is focusing on the task itself or being misled by background details.
This matters for the development of trustworthy embodied AI: artificial intelligence systems that can interact with the physical world. As robots are increasingly expected to work beyond highly controlled laboratory settings, researchers need better ways to understand when and why these systems may fail in new environments.
The research was carried out by second-year PhD student Hanxin Zhang under the supervision of Dr Daniel Z. Hao, Lecturer in AI and Robotics in the School of Computing and Mathematical Sciences and founder and principal investigator of the DANi Lab.
Dr Hao said: “Robot learning is advancing quickly, but success rate alone does not tell us whether a robot has learned the right behaviour for the right reason. A model may appear to perform well while relying on visual shortcuts that fail when the environment changes.
“Our research provides a way to examine what visual evidence actually influences robot actions. We hope this will help the wider robotics and AI community develop systems that are more interpretable, more reliable and better prepared for real-world deployment.
“Having our paper accepted to the International Conference on Machine Learning highlights the University of Leicester’s growing research strength in artificial intelligence, robotics and embodied machine learning, and its contribution to international research on trustworthy and generalisable robot learning.”
- ‘Embodied Interpretability: Linking Causal Understanding to Generalization in Vision-Language-Action Models’ was authored by Hanxin Zhang, Mingshuo Xu, Abdulqader Dhafer, Shigang Yue, Hongbiao Dong and Daniel Hao. Further details about the paper, code and examples are available on the project page.